linux解压神器:unar
用过linux的同学可能多多少少接触过linux下文档的压缩归档,通常来说我们最喜欢的还是用tar命令进行文件的归档。可有些时候,我们也不得不面对windows下常用压缩格式.zip文档。这时候同学们最先想到的肯定就是linux自带的unzip,使用命令unzip files.zip解压.zip文档一气呵成,合情合理。unzip命令在大多数情况下也不会让我们失望。解压过程优雅迅捷。可是随着我们继续使用unzip,我们会发现一个unzip致命的缺陷:当.zip包中有中文命名的文件时,解压出来的文件名会乱码。效果如图:
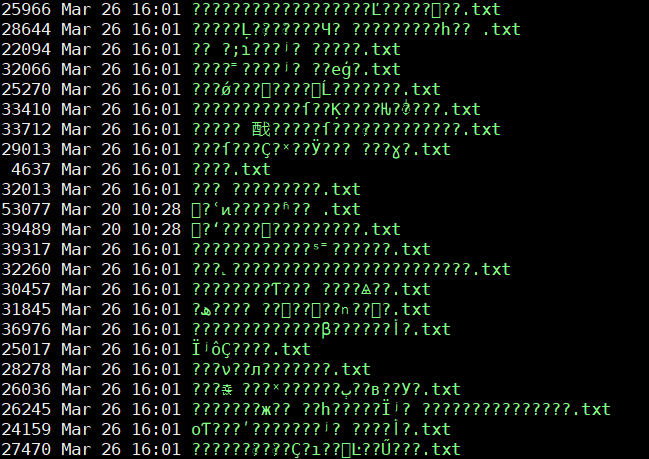
网上有人给出了原因:
原因是unzip试图将zip文件中用 oem(ibm-dos) codepage 编码的文件名转换成自己的内部编码。可惜unzip只能转换极少数几种codepage,中文的 cp936 不在其列。
甚至还给出了解决方案:
- 修改
unzip的源码:在unzip.cpp源文件的ZRESULT TUnzip::Get方法。 - 重新编译
unzip,在编译时指定参数:make -DExt_ASCII_TO_Native。 - 解压时指定参数:类似与这样
unzip -O CP936 xxx.zip (GBK, GB18030也可以)。
以上方法有些过于复杂,有些实测没有效果。这里不予推荐。
这里推荐的是:
sudo apt install unar
unar xxx.zip使用unar后,解压中文就不会出现乱码啦
如果还是出现乱码或者错误
- unar命令正常情况下可以自适应编码解压缩文件,若出现中文乱码可通过指定解压缩编码方法解决
- 使用lsar命令查看压缩包内文件,如果出现乱码情况,则指定编码再次查看
- 使用lsar -e GB18030 ,若能正常显示中文名称,则指定使用此编码解压缩文件即可
unar -e GB18030 xxx.tar.gz
via。https://zobgo.com/Linux/linux-chinese-unzip-Garbled.html
